Understanding Transformer Models in Generative AI

Delve into the architecture powering modern AI breakthroughs and learn how to build your own Transformer model
Introduction
Welcome to the next installment in our series aimed at new graduates and early-career professionals eager to dive deep into the world of Generative AI (GenAI). Today, we’ll explore the Transformer architecture, a groundbreaking model that has revolutionized natural language processing (NLP) and enabled the development of powerful language models like GPT-4.
Whether you’re an aspiring AI engineer or a data scientist, understanding Transformers is crucial for advancing your skills. We’ll break down the architecture, discuss its applications, and guide you through building a simple Transformer model using Python and PyTorch.
Table of Contents
- What are Transformer Models?
- The Limitations of Previous Models
- Key Components of the Transformer Architecture
- Applications of Transformer Models
- Building a Simple Transformer Model
- Conclusion
- Further Resources
- Advance Your Skills with GenAI Talent Academy
What are Transformer Models?
Transformer models are a type of neural network architecture introduced in the 2017 paper “Attention is All You Need” by Vaswani et al. Unlike traditional sequence models, Transformers rely entirely on self-attention mechanisms to process input data, allowing for parallelization and improved performance.
Key Innovations:
- Self-Attention Mechanism: Enables the model to weigh the importance of different parts of the input data.
- Positional Encoding: Adds information about the position of each element in the sequence.
The Limitations of Previous Models
Before Transformers, models like Recurrent Neural Networks (RNNs) and Long Short-Term Memory networks (LSTMs) were standard for sequence data. However, they had significant limitations:
- Sequential Processing: Cannot process sequences in parallel, leading to longer training times.
- Vanishing Gradients: Difficulty in learning long-range dependencies due to gradient issues.
- Fixed Memory: Limited ability to handle very long sequences.
Key Components of the Transformer Architecture
Encoder and Decoder
The Transformer model consists of two parts:
- Encoder: Processes the input sequence and generates a context-aware representation.
- Decoder: Generates the output sequence by predicting one element at a time, using the encoder’s output and previously generated elements.
Self-Attention Mechanism
Self-attention allows the model to focus on different parts of the input sequence when producing each part of the output. It computes a weighted representation of the entire sequence for each position.
Formula for Scaled Dot-Product Attention:
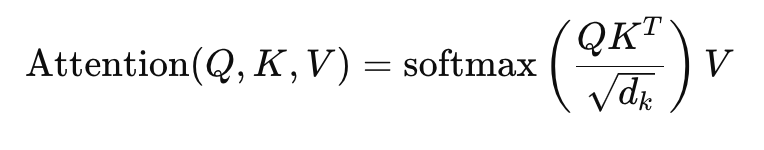
- Q: Queries
- K: Keys
- V: Values
- dk: Dimension of the keys
Positional Encoding
Since Transformers do not process sequences in order, positional encoding injects information about the position of each element in the sequence.
Sinusoidal Positional Encoding:
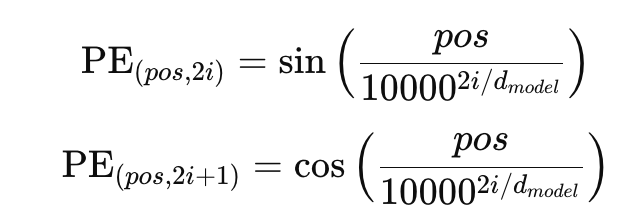
- pos: Position in the sequence
- i: Dimension index
- dmodel: Model dimensionality
Applications of Transformer Models
Transformers have led to significant advancements in various fields:
- Natural Language Processing (NLP): Language translation, sentiment analysis, text summarization.
- Computer Vision: Image captioning, object detection when combined with CNNs.
- Speech Processing: Speech recognition and synthesis.
- Protein Folding Prediction: Understanding biological sequences.
Notable Models Based on Transformers:
- BERT (Bidirectional Encoder Representations from Transformers): For language understanding tasks.
- GPT Series (Generative Pre-trained Transformer): For text generation and conversational AI.
- T5 (Text-to-Text Transfer Transformer): Unified framework for multiple NLP tasks.
Building a Simple Transformer Model
Let’s build a simplified Transformer model for a machine translation task: translating English sentences to French.
Prerequisites
- Python 3.7+
- PyTorch
- TorchText
- NumPy
- Matplotlib (for visualization, optional)
Install Dependencies:
bashCopy codepip install torch torchtext numpy matplotlib
Step 1: Data Preparation
For simplicity, we’ll use a small dataset of English-French sentence pairs.
Example Data:
data = [
('I am a student.', 'Je suis étudiant.'),
('How are you?', 'Comment ça va?'),
('Good morning.', 'Bonjour.'),
('Thank you.', 'Merci.'),
('See you later.', 'À plus tard.')
]Step 2: Importing Libraries
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchtext.vocab import build_vocab_from_iterator
from torch.utils.data import DataLoaderStep 3: Defining the Model
We’ll create a simplified version of the Transformer model using PyTorch’s nn.Transformer module.
Define Tokenizers and Vocabularies:
from torchtext.data.utils import get_tokenizer
tokenizer_en = get_tokenizer('basic_english')
tokenizer_fr = get_tokenizer('basic_english')
def yield_tokens(data_iter, language):
language_index = 0 if language == 'en' else 1
for data_sample in data_iter:
yield tokenizer_en(data_sample[language_index]) if language == 'en' else tokenizer_fr(data_sample[language_index])
vocab_en = build_vocab_from_iterator(yield_tokens(data, 'en'), specials=['<unk>', '<pad>', '<bos>', '<eos>'])
vocab_en.set_default_index(vocab_en['<unk>'])
vocab_fr = build_vocab_from_iterator(yield_tokens(data, 'fr'), specials=['<unk>', '<pad>', '<bos>', '<eos>'])
vocab_fr.set_default_index(vocab_fr['<unk>'])Define the Transformer Model:
class TransformerModel(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, d_model=512, nhead=8, num_layers=3):
super(TransformerModel, self).__init__()
self.model_type = 'Transformer'
self.src_tok_emb = nn.Embedding(src_vocab_size, d_model)
self.tgt_tok_emb = nn.Embedding(tgt_vocab_size, d_model)
self.positional_encoding = nn.Parameter(torch.empty(1, 1000, d_model))
nn.init.uniform_(self.positional_encoding, -0.1, 0.1)
self.transformer = nn.Transformer(d_model=d_model, nhead=nhead, num_encoder_layers=num_layers, num_decoder_layers=num_layers)
self.fc_out = nn.Linear(d_model, tgt_vocab_size)
self.dropout = nn.Dropout(0.1)
def forward(self, src, tgt):
src_seq_length = src.size(0)
tgt_seq_length = tgt.size(0)
src_positions = torch.arange(0, src_seq_length).unsqueeze(1).expand(src_seq_length, src.size(1))
tgt_positions = torch.arange(0, tgt_seq_length).unsqueeze(1).expand(tgt_seq_length, tgt.size(1))
src_emb = self.dropout((self.src_tok_emb(src) + self.positional_encoding[:, :src_seq_length, :]))
tgt_emb = self.dropout((self.tgt_tok_emb(tgt) + self.positional_encoding[:, :tgt_seq_length, :]))
tgt_mask = self.transformer.generate_square_subsequent_mask(tgt_seq_length).to(tgt.device)
output = self.transformer(src_emb, tgt_emb, tgt_mask=tgt_mask)
output = self.fc_out(output)
return outputStep 4: Training the Model
Define Hyperparameters and Initialize the Model:
src_vocab_size = len(vocab_en)
tgt_vocab_size = len(vocab_fr)
model = TransformerModel(src_vocab_size, tgt_vocab_size)
criterion = nn.CrossEntropyLoss(ignore_index=vocab_fr['<pad>'])
optimizer = optim.Adam(model.parameters(), lr=0.0001)Prepare Data for Training:
def data_process(data):
src_list = []
tgt_list = []
for (src_sentence, tgt_sentence) in data:
src_tensor = torch.tensor([vocab_en['<bos>']] + vocab_en(tokenizer_en(src_sentence)) + [vocab_en['<eos>']], dtype=torch.long)
tgt_tensor = torch.tensor([vocab_fr['<bos>']] + vocab_fr(tokenizer_fr(tgt_sentence)) + [vocab_fr['<eos>']], dtype=torch.long)
src_list.append(src_tensor)
tgt_list.append(tgt_tensor)
return src_list, tgt_list
src_data, tgt_data = data_process(data)Create DataLoader:
from torch.nn.utils.rnn import pad_sequence
def generate_batch(data_batch):
src_batch, tgt_batch = [], []
for src_item, tgt_item in data_batch:
src_batch.append(src_item)
tgt_batch.append(tgt_item)
src_batch = pad_sequence(src_batch, padding_value=vocab_en['<pad>'])
tgt_batch = pad_sequence(tgt_batch, padding_value=vocab_fr['<pad>'])
return src_batch, tgt_batch
batch_size = 2
train_iter = DataLoader(list(zip(src_data, tgt_data)), batch_size=batch_size, shuffle=True, collate_fn=generate_batch)Training Loop:
model.train()
num_epochs = 20
for epoch in range(num_epochs):
total_loss = 0
for src_batch, tgt_batch in train_iter:
optimizer.zero_grad()
tgt_input = tgt_batch[:-1, :]
targets = tgt_batch[1:, :].reshape(-1)
output = model(src_batch, tgt_input)
output = output.reshape(-1, output.shape[-1])
loss = criterion(output, targets)
loss.backward()
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / len(train_iter)
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {avg_loss:.4f}')Step 5: Evaluating the Model
Function to Translate a New Sentence:
def translate(model, sentence):
model.eval()
src_tensor = torch.tensor([vocab_en['<bos>']] + vocab_en(tokenizer_en(sentence)) + [vocab_en['<eos>']], dtype=torch.long).unsqueeze(1)
tgt_tensor = torch.tensor([vocab_fr['<bos>']], dtype=torch.long).unsqueeze(1)
max_len = 10
for i in range(max_len):
output = model(src_tensor, tgt_tensor)
pred_token = output.argmax(2)[-1, :].item()
tgt_tensor = torch.cat([tgt_tensor, torch.tensor([[pred_token]])], dim=0)
if pred_token == vocab_fr['<eos>']:
break
translated_sentence = ' '.join(vocab_fr.get_itos()[token] for token in tgt_tensor.squeeze().tolist()[1:-1])
return translated_sentence
# Example Usage
print(translate(model, "Thank you."))Expected Output:
Merci .Conclusion
Understanding the Transformer architecture is a significant step toward mastering modern AI techniques. While we’ve built a simplified version, real-world models are much more complex and trained on vast datasets. Nevertheless, this exercise provides a foundational understanding of how Transformers work and how you can implement them.
Keep experimenting and exploring more advanced concepts like multi-head attention, layer normalization, and pre-training techniques used in state-of-the-art models.
Further Resources
- Research Paper: “Attention is All You Need” by Vaswani et al.
- PyTorch Tutorials: Sequence-to-Sequence Modeling with nn.Transformer
- Blogs and Articles:
- The Illustrated Transformer by Jay Alammar
- Transformers from Scratch by Peter Bloem
Advance Your Skills with GenAI Talent Academy
Ready to take your GenAI expertise to the next level? The GenAI Talent Academy offers advanced programs where you’ll learn from industry-leading experts, work on cutting-edge projects, and network with professionals in the field.
Frequently Asked Questions
Q: Do I need prior experience with neural networks to understand Transformers?
A: Basic knowledge of neural networks and deep learning concepts is helpful but not strictly necessary. This post provides explanations to get you started.
Q: Why are Transformers better than RNNs for sequence tasks?
A: Transformers handle long-range dependencies more effectively and allow for parallel processing, leading to faster training times and better performance.
Q: Can Transformers be used for tasks other than NLP?
A: Yes, Transformers are being adapted for computer vision, speech processing, and even protein folding prediction.
Call to Action
If you found this tutorial insightful, share it with your peers and colleagues. Let’s learn and innovate together in the exciting field of Generative AI!
Author: GenAI Talent Academy Team
Date: October 14, 2023
Comments
Have questions or thoughts about Transformer models? Drop a comment below, and let’s discuss!
Unlock the Future with GenAI
Don’t miss the opportunity to become a leader in Generative AI. Explore our advanced programs at GenAI Talent Academy and transform your career today.
This post is part of our “Mastering GenAI: Advanced Techniques” series. Stay tuned for the next installment!